
対象読者: 動画制作の効率化に興味があるクリエイター・映像制作者
キーワード: Remotion / Gemini / VOICEVOX / Antigravity / 動画自動生成 / AI動画制作
はじめに
動画を1本仕上げるまでに、何時間を費やしていますか?
シナリオを書いて、ナレーションを録音して、画像を用意して、字幕を手打ちして、タイミングを合わせて……。制作のほとんどは、実は「繰り返し作業」で占められています。
本記事では、自律型エージェントAI Antigravity を司令塔とし、Google Gemini、VOICEVOX、そしてReactベースの動画フレームワーク Remotion を組み合わせた「全自動ドキュメンタリー動画生成パイプライン」を解説します。シナリオ執筆から最終的なMP4出力まで、一連のワークフローをどのように自動化したのかを、実際の制作事例をもとに紹介します。
その前に実際に作成した動画をご覧ください。この動画制作は筆者が平日仕事を終えた後に2時間/日、週末は5時間/日程度かけて約1週間で作成したものです。
AIがコードを書き、そのコードが動画を作る──Antigravity×Gemini×VOICEVOXで実現した自動化の全貌 – ライフ&ジョブブログ
テクノロジースタック
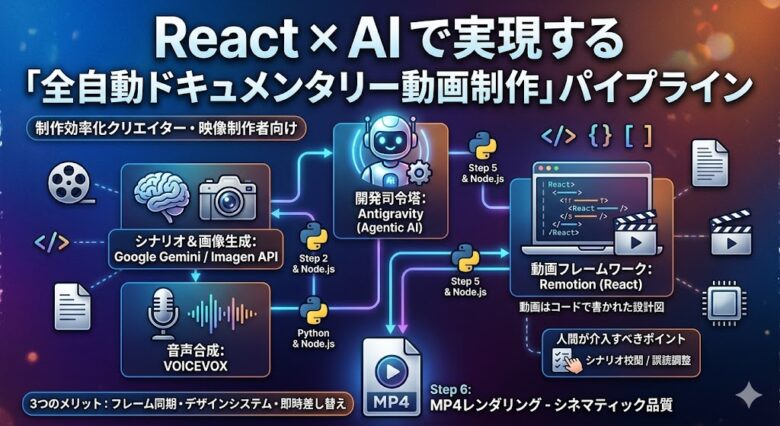
このパイプラインは、5つのコア技術で構成されています。それぞれの役割を整理すると以下のとおりです。
| レイヤー | 技術・ツール | 役割 |
|---|---|---|
| 開発司令塔 | Antigravity (Agentic AI) | パイプライン全体の自動進行・スクリプト実行・バグ修正・アセット整合性チェック |
| シナリオ & 画像生成 | Google Gemini / Imagen API | ドキュメンタリーシナリオの構造化生成、および高精細グラフィックの自動生成 |
| 音声合成 | VOICEVOX(青山龍星ほか) | ナレーション音声の合成、固有名詞・歴史用語のイントネーション制御 |
| 動画フレームワーク | Remotion (React) | React/HTML5コンポーネントをブラウザ上でレンダリングし、フレーム単位でMP4に変換 |
| 補助処理 | Python & Node.js | 音声メタデータ解析・SRT字幕生成・シナリオJSON構築など |
注目すべきは Remotion の存在です。一般的な動画編集ソフトとは異なり、Remotionは「ReactコンポーネントとしてUIを定義し、それをそのまま動画フレームとして書き出す」という発想で動作します。つまり、動画はコードで書かれた設計図であり、設計図を変えれば動画全体が自動で更新されます。
6ステップの自動生成パイプライン
以下の6フェーズを経ることで、1本のドキュメンタリー動画が完成します。
[シナリオパース] → [画像生成] → [音声合成] → [音声尺の同期] → [字幕生成] → [MP4レンダリング]Step 1 ― シナリオ構成 & Markdownパース
制作の起点となるのは、Markdown形式で記述されたシナリオ台本です。Pythonスクリプトがこのファイルを解析し、各シーンをシーンタイトル・背景画像プロンプト・ナレーションテキストの3要素に分解します。
また、長文のナレーションはチャンク(chunk)と呼ぶ発音単位に細分化して管理します。これが後工程での音声尺同期と字幕生成の精度に直結する重要な設計です。
Step 2 ― 画像の生成
Google Gemini の Imagen API を呼び出し、各シーンの演出テーマに合わせた背景グラフィックをPNGで自動生成します。解像度は2560×1440などのシネマティック品質。画像はシーンごとに命名・整理され、後工程のReactコンポーネントから自動的に参照されます。
Step 3 ― 音声合成用テキストの調整 & VOICEVOX合成
歴史ドキュメンタリーを自動生成するうえで、最も細かい調整が必要になるのがこのステップです。
VOICEVOXはデフォルト状態で難読な固有名詞を誤読しやすいため、たとえば「東端(とうたん)」「王莽(おうもう)」といった語には、あらかじめひらがな表記やアクセント記号を付加したVOICEVOX専用テキストを定義します。調整済みのテキストをVOICEVOXのローカルAPIに一括リクエストし、シーン×チャンク単位でWAVファイルをバッチ生成します。
運用ポイント: 音声波形を合成(
/synthesis)する前に、軽量な/audio_queryAPIからVOICEVOXの内部解析結果(kana)を事前取得して「読み仮名リスト」を自動生成します。これを過去の「読み修正リスト(Markdown)」と突き合わせて自動補正し、合成前に発音の整合性を確定させることで、音声合成の一発パス率を極限まで高めています。
Step 4 ― 音声尺の計測 & シナリオJSON同期
生成されたWAVファイルのバイナリ(Waveヘッダ)をPythonで解析し、ミリ秒単位の正確な音声長を取得します。これを動画フレーム数(30FPS)に換算し、シナリオJSONの durationInFrames フィールドに自動書き込みします。
シーン全体の尺は、そのシーンに属する全チャンクの合計として計算されます。「ナレーションが終わった瞬間に映像が切り替わる」というフレームパーフェクトな同期がここで実現します。
Step 5 ― SRT字幕の生成 & タイトルカード作成
Step 4で同期されたJSONデータをもとに、SRT形式の字幕ファイルを自動生成します。タイムコードはフレーム単位で記述されるため、字幕のズレは原理的に発生しません。
また、各パートの区切りに挿入する4秒間のタイトルカード画像も自動合成されます(グラデーション背景+テキスト合成)。
Step 6 ― Remotionによるレンダリング
すべてのアセット(画像・音声・字幕・BGM)が揃ったら、いよいよ最終レンダリングです。
Reactコンポーネント src/Composition.tsx がシナリオJSONを読み込み、以下の処理を動的に実行します。
- シーンごとに背景画像を配置
- ズーム・パンのアニメーションを付加
- チャンク単位でWAV音声を
<Sequence>として配置 - 字幕テキストをフレーム同期で重ね合わせ
- フェードイン・フェードアウト処理
最後にrenderMedia()を実行すると、仮想ブラウザが1フレームずつ描画し、それを結合してシネマティックなMP4ファイルが出力されます。
主要ファイルの構成
パイプラインで使用するファイルは、役割ごとに明確に整理されています。
| 分類 | ファイル名・パス | 役割 |
|---|---|---|
| マスターシナリオ(src) | src/auto_scenario_ch5_sequel.json | Reactが直接読み込む、シーン・チャンク・BGM定義を含む設定ファイル |
| マスターシナリオ(public) | public/auto_scenario_ch5_sequel.json | 音声合成スクリプトや外部バッチ処理が読み書きするミラーファイル |
| 動画エントリポイント | src/Root.tsx | コンポジションを定義し、総フレーム数を動的算出するReactルート |
| 動画構成コンポーネント | src/Composition.tsx | 画像・音声・字幕・アニメーションを定義した中核UIコード |
| 音声アセット | public/audio/ch5_sequel/scene_XX_chunk_YY.wav | シーン内の個別センテンス用ナレーション音声 |
| 画像アセット | public/images/ch5_sequel/scene_XX.png | AI生成のシーン別背景グラフィック |
| タイトルアセット | public/images/ch5_sequel/part_X_title.png | パート開始時の自動生成タイトルカード画像 |
| 字幕ファイル | out/ch5_sequel_subtitles.srt | 映像・音声と完全同期したマスター字幕 |
| 音声同期スクリプト | scratch/sync_actual_durations.py | WAVファイルの実尺を計測してJSONを更新するPythonスクリプト |
| 字幕生成スクリプト | scratch/generate_ch5_sequel_srt.py | JSONから音声同期済みSRTを生成する補助スクリプト |
| レンダリングスクリプト | render_video_ch5_sequel.mjs | RemotionレンダラーからMP4を出力するNodeスクリプト |
| 最終成果物 | out/chapter5_sequel_final.mp4 | パイプラインの最終出力動画 |
src/ と public/ にシナリオJSONが2つ存在するのがポイントです。Reactコンポーネントが参照する src/ 側と、外部スクリプトが更新する public/ 側を分離することで、レンダリング中に設定ファイルが書き変わって壊れるという事故を防いでいます。
コードによる動画編集の3つのメリット
1. フレームパーフェクトな音声同期
WAVファイルの実尺(ミリ秒)を直接フレーム数に変換して設定ファイルに書き込む設計により、ナレーションの終わりと映像の切り替わりが1フレームもズレません。従来の手動タイミング合わせは不要です。
2. デザインシステムによる統一されたビジュアル
フォントサイズ・字幕背景色・フェードイン速度などのスタイルは、ReactコンポーネントのCSSとして一元管理されています。動画本数が増えても、シリーズ全体のトーン&マナーが自動的に統一されます。
3. 差し替えが即座に反映される
シナリオテキストの一部修正・画像の差し替えが発生した場合、該当の設定ファイルやアセットを更新してスクリプトを実行するだけで、数万フレームの動画が自動で再生成されます。「1行直すために全編を再編集し直す」という事態が起きません。
人間が介入すべきポイント
全自動とはいえ、品質を保つうえで人間のレビューが必要な箇所が2点あります。
シナリオの校閲: Geminiが生成したシナリオの歴史的正確性・文脈の自然さは、必ず人間が確認します。生成AIは流暢な文章を書きますが、事実誤認が混入する場合があります。
誤読の事前検知と調整: VOICEVOXの読み誤りは、音声(WAV)を合成する前に「予定される読み仮名」をAPI経由で自動解析して事前チェックします。WAV生成前に誤読を検知して「音声用テキスト(ひらがな・アクセント調整済)」へ差し替えるため、無駄な音声合成や手戻りが発生しません。人間は、Antigravityが事前抽出した発音レポート(差分)に目を通し、新出の難読用語のルールを確認するだけで済みます。
まとめ
本記事で紹介したパイプラインの要点は以下のとおりです。
- シナリオ → 画像 → 音声 → 字幕 → 動画 の全工程をスクリプトで自動化
- Remotion を使うことで、動画の設計がReactコードとして管理でき、差し替えや修正が容易
- フレーム単位の音声同期により、手動タイミング調整が一切不要
- Antigravity(エージェントAI) がスクリプト実行・整合性チェックを自律的に管理
このアーキテクチャの最大の価値は「再現性」です。一度パイプラインを構築すれば、テーマを変えるだけで同品質の動画が何本でも量産できます。教育コンテンツ・企業PR・情報系チャンネルなど、定期的に動画を制作する用途に特に適しています。
本パイプラインの実装では、AIエージェントによるコード生成・修正と人間によるコンテンツ校閲を組み合わせることで、クオリティと生産性の両立を目指しています。


コメント