

Webサイトからデータをスクレイピングし、Googleスプレッドシートに自動的に転記するコードを実際に作成し、その解説をします。
PythonによるWebスクレイピングの実践ーその1(導入編) – ライフ&ジョブブログ (life-and-job.com)
サイトから実際に抽出してみよう
実際にWebサイトから情報を抽出してみます。ここでは住友林業様の以下の営業拠点の一覧ページを使わせて頂きます(スクレイピングが禁止されていないページであることを確認済です)。
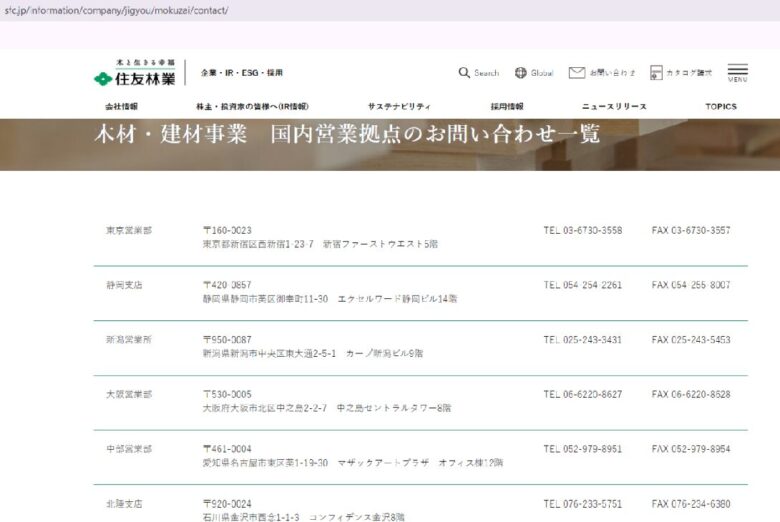
このページから拠点名、住所、FAX番号の情報を抽出して、最終的にGoogleスプレッドシートに転記するコードについて説明していきます。
スクレイピングのコードを実行してみる
まずは、コードを実行してみましょう。使用するライブラリはBeautifulSoup、Pandas、Requests、gspreadです。インストールされていなければ、初めにインストールを行なっておいてください。
pip install beautifulsoup4 pandas requests oauth2client gspread gspread-dataframe
以下のコードを実行します。すると、
from bs4 import BeautifulSoup
import pandas as pd
import requests
from oauth2client.service_account import ServiceAccountCredentials
import gspread
from gspread_dataframe import set_with_dataframe
# スクレイピングするURLを設定
url = "https://sfc.jp/information/company/jigyou/mokuzai/contact/"
# リクエストとパース
response = requests.get(url)
response.encoding = 'utf-8'
html_text = response.text
soup = BeautifulSoup(html_text, "html.parser")
# データを格納するリストを初期化
data = []
# 拠点情報を抽出
for row in soup.find_all("tr", class_="detailTable__item"):
office_name = row.find("td", class_="detailTable__text detailTable__SpHeading").get_text(strip=True)
address = row.find("td", {"data-title": "住所"}).get_text(separator=" ", strip=True)
fax = row.find("td", {"data-title": "FAX番号"}).get_text(strip=True)
# データをリストに追加
data.append({
"拠点名": office_name,
"住所": address,
"FAX": fax
})
# データフレームに変換
df = pd.DataFrame(data)
# データフレームの表示
print(df)
以下の結果が表示されると思います。

コードの解説
コードの詳細解説をしていきます。
ライブラリのインポート
from bs4 import BeautifulSoup
import pandas as pd
import requests
from oauth2client.service_account import ServiceAccountCredentials
import gspread
from gspread_dataframe import set_with_dataframe
必要なライブラリをインポートします。BeautifulSoupはHTMLのパース(解析)、pandasはデータフレームの操作、requestsはHTTPリクエストの送信、oauth2clientとgspreadはGoogleスプレッドシートAPIの操作に使用します。
URLの設定とHTMLの取得
url = "https://sfc.jp/information/company/jigyou/mokuzai/contact/"
response = requests.get(url)
response.encoding = 'utf-8'
html_text = response.text
soup = BeautifulSoup(html_text, "html.parser")
スクレイピング対象のURLを設定し、requestsライブラリでHTMLを取得します。その後、BeautifulSoupでHTMLをパースします。
データの抽出
data = []
for row in soup.find_all("tr", class_="detailTable__item"):
office_name = row.find("td", class_="detailTable__text detailTable__SpHeading").get_text(strip=True)
address = row.find("td", {"data-title": "住所"}).get_text(separator=" ", strip=True)
fax = row.find("td", {"data-title": "FAX番号"}).get_text(strip=True)
data.append({
"拠点名": office_name,
"住所": address,
"FAX": fax
})
BeautifulSoupを使って、指定したクラスや属性を持つ要素から拠点名、住所、FAX番号を抽出し、リストに格納します。
要素の特定方法について、後ほどもう少し詳しく説明します。
データフレームへの変換
df = pd.DataFrame(data)
print(df)
抽出したデータをpandasのデータフレームに変換し、表示します。
要素の特定(サイトのHTML構造の調査)
抽出したい情報がどこにあるか探すには、ブラウザーの開発者ツールを利用します。ここではGoogle Chromeの開発者ツールで説明します。
Webサイト画面で右クリックすると、下のボックスが現れ、「検証」を選びます。
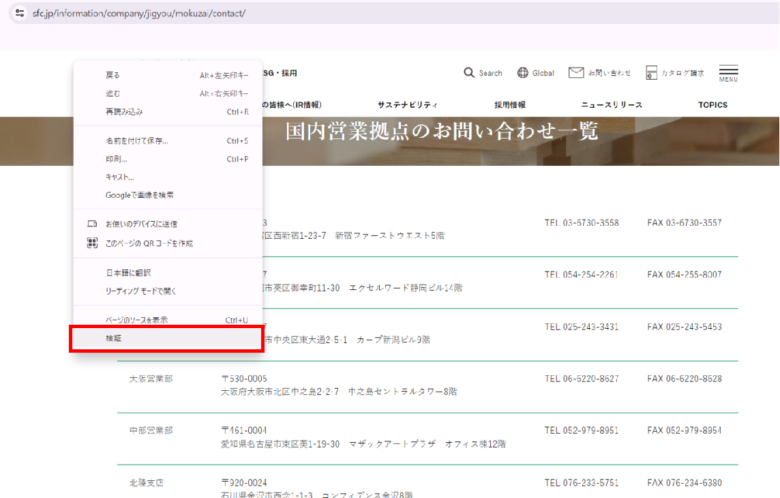
開発者ツールの操作方法はここでは説明しませんが、下のような画面が現れます。ここでサイト画面で見たい箇所をクリックすると、その要素が表示されて特定することができます。
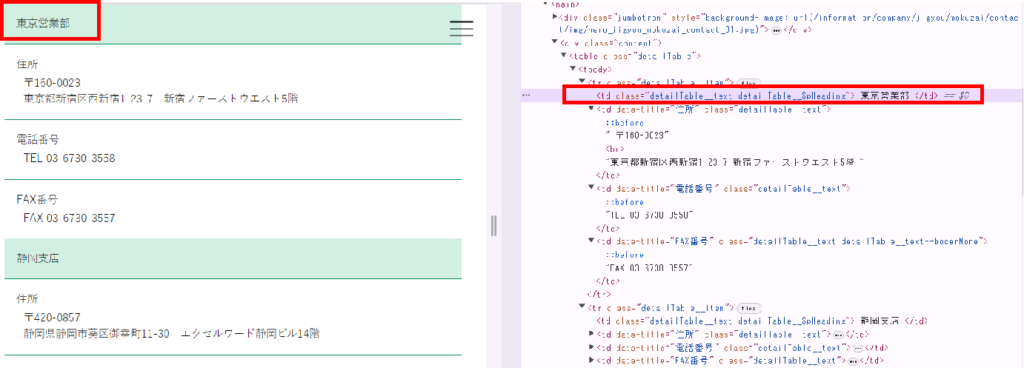
下の画面で、紫色の文字がタグ名(td、table、mainなど)、オレンジ色の文字が属性名(class、data-titleなど)になり、これを指定することでデータが抽出されます。他の拠点もすべて同じように情報が格納されているので、全拠点情報が得られることになります。
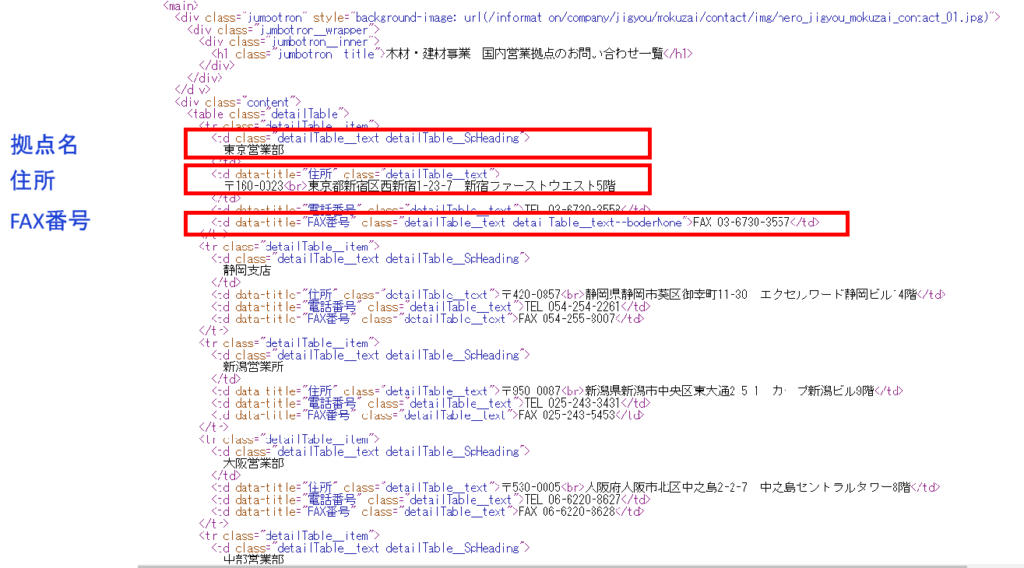
このようにして、WebサイトのURLを指定し、抽出したい要素を特定することができれば、情報を抽出することが可能になります。
注)同じ属性でも、classとdata-titleでコードが異なっています。
data-titleのように、data-というプレフィックスがついた属性はカスタムデータ属性と呼ばれ、以下のような書き方(attrsパラメータ)で指定するようです。
soup.find("td", class_="detailTable__text detailTable__SpHeading")
soup.find("td", {"data-title": "住所"})
Googleスプレッドシートへの転記
抽出したデータを転記するコードは以下のようになります。
# Google Sheets APIの設定
scope = ["https://spreadsheets.google.com/feeds", "https://www.googleapis.com/auth/drive"]
credentials = ServiceAccountCredentials.from_json_keyfile_name('path_to_your_service_account.json', scope)
client = gspread.authorize(credentials)
# スプレッドシートの取得
spreadsheet = client.open('your_spreadsheet_name')
worksheet = spreadsheet.sheet1
# DataFrameをスプレッドシートに書き込む
set_with_dataframe(worksheet, df)以下については、個別に設定します。
"path/to/your-service-account-file.json":ダウンロードしたサービスアカウントのJSONファイルのパス
"your-spreadsheet-name":アクセスしたいスプレッドシートの名前
実行すると、以下のようにスプレッドシートへ転記されました。

Google Sheets APIを使用するための設定方法
Google Sheets APIの設定をする場合は、以下の手順で行ってください。
Google Cloud プロジェクトの作成
1.Google Cloud Consoleにアクセスします: https://console.cloud.google.com/
2.プロジェクトを作成します:
- ナビゲーションメニューの「プロジェクトを選択」をクリックし、「新しいプロジェクト」をクリックします。
- プロジェクト名を入力し、「作成」をクリックします。
Google Sheets APIを有効にする
1.APIとサービスのダッシュボードに移動します。
2.「ライブラリ」をクリックします。
3.「Google Sheets API」を検索して選択し、「有効にする」をクリックします。
認証情報を設定する
1.APIとサービスのダッシュボードに戻り、「認証情報」をクリックします。
2.「認証情報を作成」をクリックし、「サービスアカウント」を選択します。
3.サービスアカウントの名前と説明を入力し、「作成」をクリックします。
4.サービスアカウントに「役割」を付与します。通常、「プロジェクト」>「編集者」または「オーナー」を選択します。
5.「キーを作成」をクリックし、「JSON」形式でダウンロードします。このファイルを安全な場所に保存します。後でPythonコードで使用します。
Google Sheets API用のPython環境を設定する
1.必要なPythonライブラリをインストールします:
pip install gspread oauth2client
2.ダウンロードしたJSONキーをプロジェクトディレクトリに配置します。
3.Pythonコードを作成します。
スプレッドシートの共有設定
1.スプレッドシートを開きます。
2.右上の「共有」ボタンをクリックします。
3.サービスアカウントのメールアドレス(ダウンロードしたJSONファイルの中にあります)を入力し、閲覧権限または編集権限を付与します。
まとめ
今回は、WebサイトからデータをスクレイピングしてGoogleスプレッドシートに自動転記する方法について解説しました。実際の企業サイトの営業拠点一覧ページから拠点名、住所、FAX番号の情報を抽出し、Googleスプレッドシートに転記するためのPythonコードを紹介しました。以下がポイントとなります。
- 必要なライブラリのインストール: BeautifulSoup、Pandas、Requests、gspreadなどをインストールして、スクレイピングとGoogleスプレッドシートの操作を可能にしました。
- HTMLの取得とパース: Requestsを使用して指定したURLのHTMLを取得し、BeautifulSoupでパースしました。
- データの抽出: BeautifulSoupを使って、指定したクラスや属性を持つ要素から必要な情報を抽出し、リストに格納しました。
- データのデータフレームへの変換: Pandasを使用して、抽出したデータをデータフレームに変換し、整形しました。
- Googleスプレッドシートへの転記: gspreadとgspread_dataframeを使用して、データフレームの内容をGoogleスプレッドシートに転記しました。
- Google Sheets APIの設定: Google Cloud ConsoleでのAPI有効化、サービスアカウントの作成、認証情報の設定など、必要な設定手順を詳しく説明しました。
これらの手順を踏むことで、定期的なデータ収集や自動化の一環として、ウェブサイトからのデータ抽出を効率的に行うことができます。スクレイピングを行う際には、対象ウェブサイトの利用規約やロボット排除規定(robots.txt)を確認し、適切に利用することを心掛けてください。


コメント